- Real-time model health: a dynamic engine tracks model availability, utilization, speed, error rates, and cost. A model may be capable of handling a task, but that does not mean it is the best choice at that moment. Auto takes current system conditions into account so Copilot can route to a model that is both capable and ready to respond.
- Task-aware routing with HyDRA: a routing model that considers factors like reasoning depth, code complexity, debugging difficulty, and tool orchestration needs. HyDRA identifies models that can meet the quality bar for the task, then chooses the best fit among them.
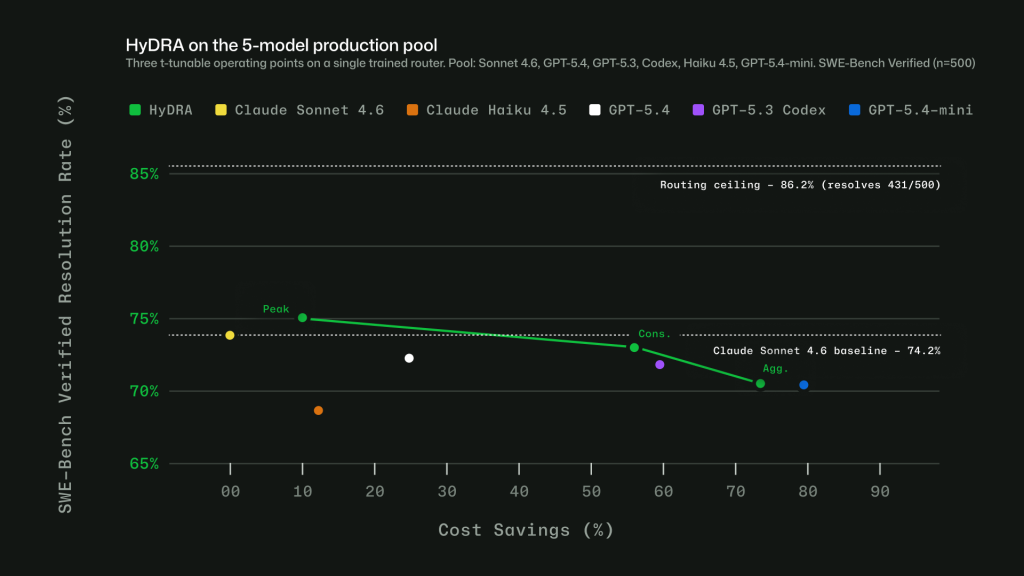 Figure 1: Three HyDRA operating points illustrate tunability: (Peak) exceeds Sonnet at 12.9% savings; (Agg.) balances quality for 72.5% savings.
Figure 1: Three HyDRA operating points illustrate tunability: (Peak) exceeds Sonnet at 12.9% savings; (Agg.) balances quality for 72.5% savings. 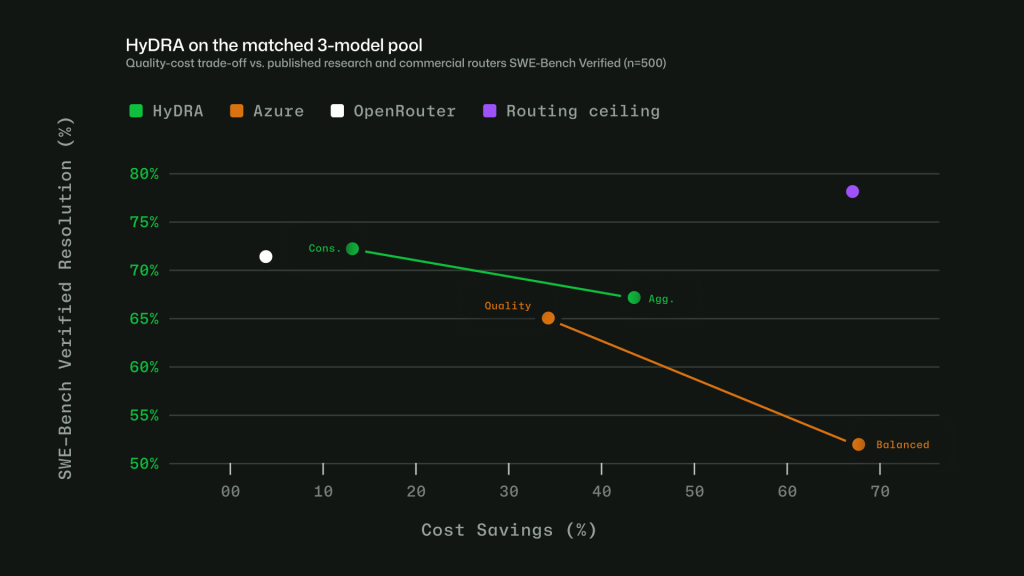 Figure 2: HyDRA (Cons.) ties OpenRouter Auto on resolution rate (70.8%) at 3.3x the savings. HyDRA (Agg.) outperforms both Azure Foundry operating modes. Taken together, these signals let Auto avoid a one-size-fits-all approach. The point is not to send every task to the biggest model, or every task to the cheapest one. It is to choose the model that fits the work. Making Auto work in practice Getting routing right in evaluations is only part of the problem. To make Auto useful in real workflows, we also had to account for how developers actually use Copilot: conversations get longer, context builds up, tasks shift, and developers work in many languages. Cache-aware routing. Switching models on every turn may sound flexible, but it can work against efficiency. When a conversation stays on the same model, the prompt prefix can be cached and reused across turns. Switching models mid-conversation breaks that cache, which can cost more than the routing change saves. Auto avoids that by routing at natural cache boundaries: on the first turn, when there is no cache to lose, and after compaction, when Copilot summarizes older turns and the prompt prefix resets. Between those points, the selected model stays in place so the cache can keep building. Routing across languages. Copilot serves developers around the world, so routing has to work in languages other than English. We trained the routing model on conversations across 16 language families, including CJK, European, and others. In evaluations, routing accuracy stayed within four points of the English baseline across language groups, with no statistically significant quality gap.
Figure 2: HyDRA (Cons.) ties OpenRouter Auto on resolution rate (70.8%) at 3.3x the savings. HyDRA (Agg.) outperforms both Azure Foundry operating modes. Taken together, these signals let Auto avoid a one-size-fits-all approach. The point is not to send every task to the biggest model, or every task to the cheapest one. It is to choose the model that fits the work. Making Auto work in practice Getting routing right in evaluations is only part of the problem. To make Auto useful in real workflows, we also had to account for how developers actually use Copilot: conversations get longer, context builds up, tasks shift, and developers work in many languages. Cache-aware routing. Switching models on every turn may sound flexible, but it can work against efficiency. When a conversation stays on the same model, the prompt prefix can be cached and reused across turns. Switching models mid-conversation breaks that cache, which can cost more than the routing change saves. Auto avoids that by routing at natural cache boundaries: on the first turn, when there is no cache to lose, and after compaction, when Copilot summarizes older turns and the prompt prefix resets. Between those points, the selected model stays in place so the cache can keep building. Routing across languages. Copilot serves developers around the world, so routing has to work in languages other than English. We trained the routing model on conversations across 16 language families, including CJK, European, and others. In evaluations, routing accuracy stayed within four points of the English baseline across language groups, with no statistically significant quality gap. 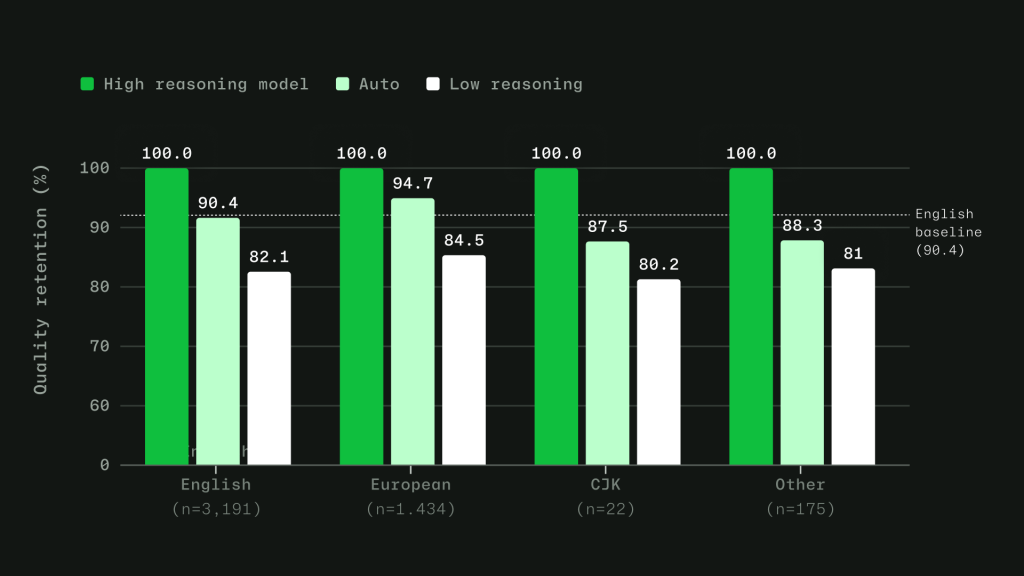 Figure 3: Intelligent routing stays within 4 points of English baseline. Model evaluations across English, European, CJK, and other script families, based on a held out evaluation set sampled from production VS Code chat telemetry across 19 languages. Learning when escalation matters. Instead of labeling tasks as simply “easy” or “hard,” we trained the router to learn where models actually diverge. For each training query, responses from a less capable model and a more capable model are scored across quality dimensions. The router learns when the stronger model adds value, and when a more efficient model can produce an equally good result. For context-dependent messages in longer agentic sessions, the router is trained on complete multi-turn conversations, including the original user intent, recent assistant responses, and conversation metadata. Auto with task intent is expanding Auto with task intent is already live in Visual Studio Code, github.com, and mobile. It gives Copilot more signal about the kind of work you are doing, whether that is coding, debugging, planning, or using tools, so it can make a better model choice for the task. We are continuing to expand that experience across Copilot. Next, we are bringing Auto with task intent to more surfaces and adding more ways for teams to make Auto the default.
Figure 3: Intelligent routing stays within 4 points of English baseline. Model evaluations across English, European, CJK, and other script families, based on a held out evaluation set sampled from production VS Code chat telemetry across 19 languages. Learning when escalation matters. Instead of labeling tasks as simply “easy” or “hard,” we trained the router to learn where models actually diverge. For each training query, responses from a less capable model and a more capable model are scored across quality dimensions. The router learns when the stronger model adds value, and when a more efficient model can produce an equally good result. For context-dependent messages in longer agentic sessions, the router is trained on complete multi-turn conversations, including the original user intent, recent assistant responses, and conversation metadata. Auto with task intent is expanding Auto with task intent is already live in Visual Studio Code, github.com, and mobile. It gives Copilot more signal about the kind of work you are doing, whether that is coding, debugging, planning, or using tools, so it can make a better model choice for the task. We are continuing to expand that experience across Copilot. Next, we are bringing Auto with task intent to more surfaces and adding more ways for teams to make Auto the default. - Auto with task intent is coming to Copilot CLI, GitHub App, and additional IDEs.
- Copilot Free and Student plans will be simplified to leverage Auto as the only model selection option.
- Admin controls will let organizations set Auto as the default or enforce Auto as the only option.
- Start with Auto. Auto is the strong default for many tasks because it chooses a model based on what you are trying to do, without making you pick one manually every time.
- Keep context focused. Start a new session when you switch tasks, compact long-running sessions when needed, and mention the files you want Copilot to use when you already know where the relevant code lives. Less unnecessary context means more of the session goes toward the actual work.
- Avoid changing models or settings mid-session. Switching models, reasoning levels, context size, or tool configuration can break cache reuse and make Copilot rebuild context. Set up the session the way you want it, then keep related work together.
- Plan before parallelizing. For larger tasks, ask Copilot to plan first. Parallel agents can be useful when work can truly be split up, but they also consume credits in parallel, so use them deliberately.
- Use only the tools you need. Tools and MCP servers are powerful, but broad toolsets can add extra context. Enable what is relevant to the task and turn off what you do not need. Check out agent finder in GitHub Copilot to help streamline your tool usage.
- Check your usage. Your AI usage page shows where credits are going across features and models. In Copilot CLI, session-level usage can also help you spot expensive patterns while you work.
Source: https://github.blog/ai-and-ml/github-co ... l-routing/